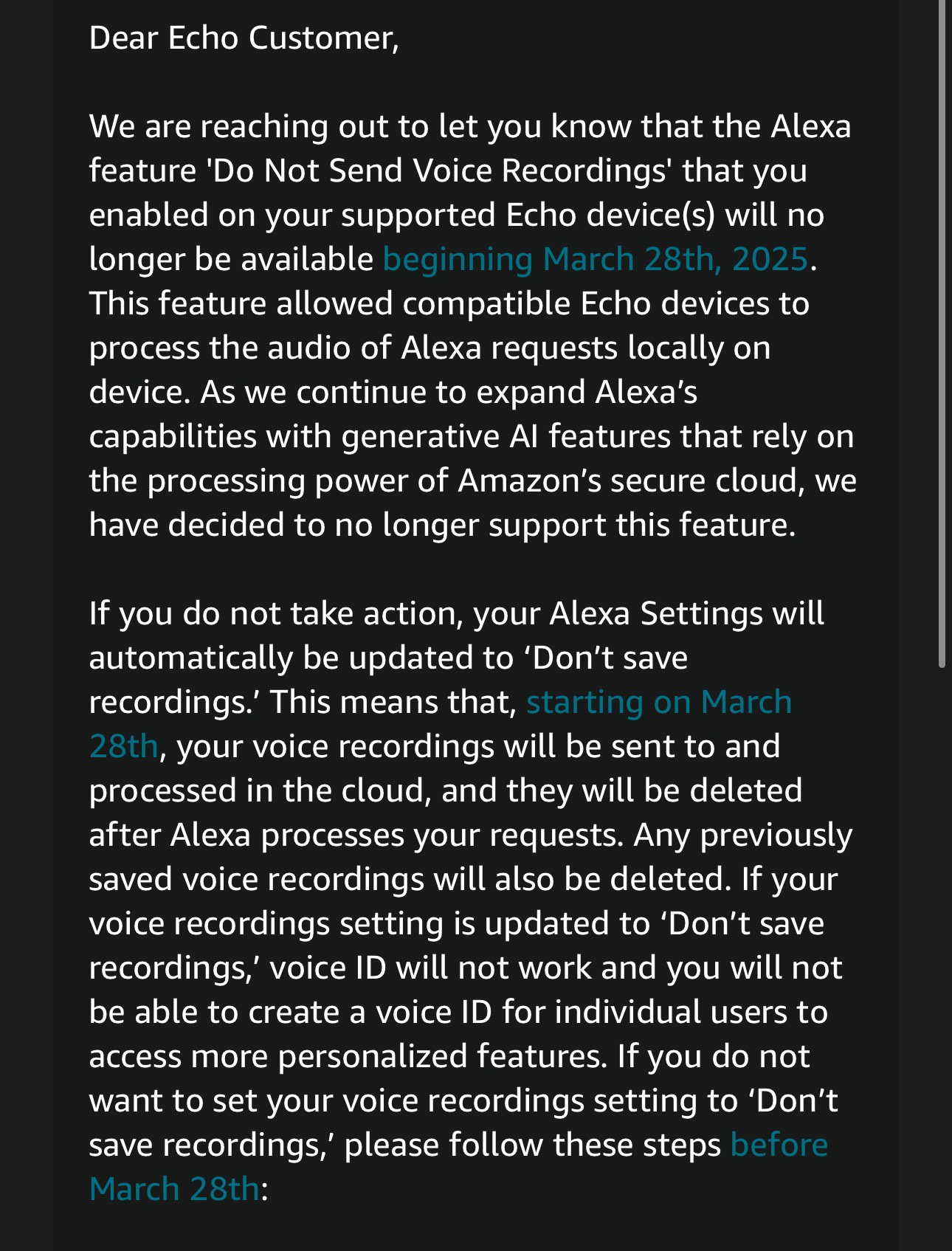
If you look at the article, it was only ever possible to do local processing with certain devices and only in English. I assume that those are the ones with enough compute capacity to do local processing, which probably made them cost more, and that the hardware probably isn’t capable of running whatever models Amazon’s running remotely.
I think that there’s a broader problem than Amazon and voice recognition for people who want self-hosted stuff. That is, throwing loads of parallel hardware at something isn’t cheap. It’s worse if you stick it on every device. Companies — even aside from not wanting someone to pirate their model running on the device — are going to have a hard time selling devices with big, costly, power-hungry parallel compute processors.
What they can take advantage of is that for a lot of tasks, the compute demand is only intermittent. So if you buy a parallel compute card, the cost can be spread over many users.
I have a fancy GPU that I got to run LLM stuff that ran about $1000. Say I’m doing AI image generation with it 3% of the time. It’d be possible to do that compute on a shared system off in the Internet, and my actual hardware costs would be about $33. That’s a heckofa big improvement.
And the situation that they’re dealing with is even larger, since there might be multiple devices in a household that want to do parallel-compute-requiring tasks. So now you’re talking about maybe $1k in hardware for each of them, not to mention the supporting hardware like a beefy power supply.
This isn’t specific to Amazon. Like, this is true of all devices that want to take advantage of heavyweight parallel compute.
I think that one thing that it might be worth considering for the self-hosted world is the creation of a hardened network parallel compute node that exposes its services over the network. So, in a scenario like that, you would have one (well, or more, but could just have one) device that provides generic parallel compute services. Then your smaller, weaker, lower-power devices — phones, Alexa-type speakers, whatever — make use of it over your network, using a generic API. There are some issues that come with this. It needs to be hardened, can’t leak information from one device to another. Some tasks require storing a lot of state — like, AI image generation requires uploading a large model, and you want to cache that. If you have, say, two parallel compute cards/servers, you want to use them intelligently, keep the model loaded on one of them insofar as is reasonable, to avoid needing to reload it. Some devices are very latency-sensitive — like voice recognition — and some, like image generation, are amenable to batch use, so some kind of priority system is probably warranted. So there are some technical problems to solve.
But otherwise, the only real option for heavy parallel compute is going to be sending your data out to the cloud. And even if you don’t care about the privacy implications or the possibility of a company going under, as I saw some home automation person once point out, you don’t want your light switches to stop working just because your Internet connection is out.
Having per-household self-hosted parallel compute on one node is still probably more-costly than sharing parallel compute among users. But it’s cheaper than putting parallel compute on every device.
Linux has some highly-isolated computing environments like seccomp that might be appropriate for implementing the compute portion of such a server, though I don’t know whether it’s too-restrictive to permit running parallel compute tasks.
In such a scenario, you’d have a “household parallel compute server”, in much the way that one might have a “household music player” hooked up to a house-wide speaker system running something like mpd or a “household media server” providing storage of media, or suchlike.


{kind=link}
If you look at the article, it was only ever possible to do local processing with certain devices and only in English. I assume that those are the ones with enough compute capacity to do local processing, which probably made them cost more, and that the hardware probably isn’t capable of running whatever models Amazon’s running remotely.
I think that there’s a broader problem than Amazon and voice recognition for people who want self-hosted stuff. That is, throwing loads of parallel hardware at something isn’t cheap. It’s worse if you stick it on every device. Companies — even aside from not wanting someone to pirate their model running on the device — are going to have a hard time selling devices with big, costly, power-hungry parallel compute processors.
What they can take advantage of is that for a lot of tasks, the compute demand is only intermittent. So if you buy a parallel compute card, the cost can be spread over many users.
I have a fancy GPU that I got to run LLM stuff that ran about $1000. Say I’m doing AI image generation with it 3% of the time. It’d be possible to do that compute on a shared system off in the Internet, and my actual hardware costs would be about $33. That’s a heckofa big improvement.
And the situation that they’re dealing with is even larger, since there might be multiple devices in a household that want to do parallel-compute-requiring tasks. So now you’re talking about maybe $1k in hardware for each of them, not to mention the supporting hardware like a beefy power supply.
This isn’t specific to Amazon. Like, this is true of all devices that want to take advantage of heavyweight parallel compute.
I think that one thing that it might be worth considering for the self-hosted world is the creation of a hardened network parallel compute node that exposes its services over the network. So, in a scenario like that, you would have one (well, or more, but could just have one) device that provides generic parallel compute services. Then your smaller, weaker, lower-power devices — phones, Alexa-type speakers, whatever — make use of it over your network, using a generic API. There are some issues that come with this. It needs to be hardened, can’t leak information from one device to another. Some tasks require storing a lot of state — like, AI image generation requires uploading a large model, and you want to cache that. If you have, say, two parallel compute cards/servers, you want to use them intelligently, keep the model loaded on one of them insofar as is reasonable, to avoid needing to reload it. Some devices are very latency-sensitive — like voice recognition — and some, like image generation, are amenable to batch use, so some kind of priority system is probably warranted. So there are some technical problems to solve.
But otherwise, the only real option for heavy parallel compute is going to be sending your data out to the cloud. And even if you don’t care about the privacy implications or the possibility of a company going under, as I saw some home automation person once point out, you don’t want your light switches to stop working just because your Internet connection is out.
Having per-household self-hosted parallel compute on one node is still probably more-costly than sharing parallel compute among users. But it’s cheaper than putting parallel compute on every device.
Linux has some highly-isolated computing environments like seccomp that might be appropriate for implementing the compute portion of such a server, though I don’t know whether it’s too-restrictive to permit running parallel compute tasks.
In such a scenario, you’d have a “household parallel compute server”, in much the way that one might have a “household music player” hooked up to a house-wide speaker system running something like mpd or a “household media server” providing storage of media, or suchlike.