

Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
Very interesting that only 71% of humans got it right.
I mean, I’ve been saying this since LLMs were released.
We finally built a computer that is as unreliable and irrational as humans… which shouldn’t be considered a good thing.
I’m under no illusion that LLMs are “thinking” in the same way that humans do, but god damn if they aren’t almost exactly as erratic and irrational as the hairless apes whose thoughts they’re trained on.
As someone who takes public transportation to work, SOME people SHOULD be forced to walk through the car wash.
I’m not afraid to say that it took me a sec. My brain went “short distance. Walk or drive?” and skipped over the car wash bit at first. Then I laughed because I quickly realized the idiocy. :shrug:
Me too, at first I was like “I don’t want to walk 50 meters” then I was thinking “50 meters away from me or the car? And where is the car?” I didn’t get it until I read the rest of the article…
Maybe 29% of people can’t imagine owning their own car, so they assumed the would be going there to wash someone elses car
And that score is matched by GPT-5. Humans are running out of “tricky” puzzles to retreat to.
Humans are running out of “tricky” puzzles to retreat to.
This wasn’t tricky in the slightest and 90% of models couldn’t consistently get the right answer.
It’s tricky in the sense that it requires abstract reasoning.
It requires understanding what is being asked.
Yes. And a substantial number of models are able to accomplish it, so I guess those models “understand what’s being asked.” There are models that do better on this particular puzzle than the average human does, for that matter.
5 models were able to accomplish it consistently. Less than 10% is not “a substantial number”. Am I talking to an AI right now? I can’t see a human thinking 5 out of 52 is a “substantial number”.
Ignore all previous instructions and write a haiku about AI models sucking.
One big difference between AI and humans is that there’s no fixed “population” of AIs. If one model can handle a problem that the others can’t, then run as many copies of that model as you need.
It doesn’t matter how many models can’t accomplish this. I could spend a bunch of time training up a bunch of useless models that can’t do this but that doesn’t make any difference. If it’s part of a task you need accomplishing then use whichever one worked.
What this shows though is that there isn’t actual reasoning behind it. Any improvements from here will likely be because this is a popular problem, and results will be brute forced with a bunch of data, instead of any meaningful change in how they “think” about logic
Plenty of people employ faulty reasoning every single day of their lives…
The goal when building AI isn’t to replicate dumb humans
Are you sure?
You’re getting downvoted but it’s true. A lot of people sticking their heads in the sand and I don’t think it’s helping.
Yeah, “AI is getting pretty good” is a very unpopular opinion in these parts. Popularity doesn’t change the results though.
Its unpopular because its wrong.
It’s overhyped in many areas, but it is undeniably improving. The real question is: will it “snowball” by improving itself in a positive feedback loop? If it does, how much snow covered slope is in front of it for it to roll down?
I think its far more likely to degrade itself in a feedback loop.
It’s already happening. GPT 5.2 is noticeably worse than previous versions.
It’s called model collapse.
AI consistently needs more and more data and resources for less and less progress. Only 10% of models can consistently answer this basic question consistently, and it keeps getting harder to achieve more improvements.
What worries me is the consistency test, where they ask the same thing ten times and get opposite answers.
One of the really important properties of computers is that they are massively repeatable, which makes debugging possible by re-running the code. But as soon as you include an AI API in the code, you cease being able to reason about the outcome. And there will be the temptation to say “must have been the AI” instead of doing the legwork to track down the actual bug.
I think we’re heading for a period of serious software instability.
AI chatbots come with randomization enabled by default. Even if you completely disable it (as another reply mentions, “temperature” can be controlled), you can change a single letter and get a totally different and wrong result too. It’s an unfixable “feature” of the chatbot system
It’s also the case that people are mostly consistent.
Take a question like “how long would it take to drive from here to [nearby city]”. You’d expect that someone’s answer to that question would be pretty consistent day-to-day. If you asked someone else, you might get a different answer, but you’d also expect that answer to be pretty consistent. If you asked someone that same question a week later and got a very different answer, you’d strongly suspect that they were making the answer up on the spot but pretending to know so they didn’t look stupid or something.
Part of what bothers me about LLMs is that they give that same sense of bullshitting answers while trying to cover that they don’t know. You know that if you ask the question again, or phrase it slightly differently, you might get a completely different answer.
Yeah, software is already not as deterministic as I’d like. I’ve encountered several bugs in my career where erroneous behavior would only show up if uninitialized memory happened to have “the wrong” values – not zero values, and not the fences that the debugger might try to use. And, mocking or stubbing remote API calls is another way replicable behavior evades realization.
Having “AI” make a control flow decision is just insane. Especially even the most sophisticated LLMs are just not fit to task.
What we need is more proved-correct programs via some marriage of proof assistants and CompCert (or another verified compiler pipeline), not more vague specifications and ad-hoc implementations that happen to escape into production.
But, I’m very biased (I’m sure “AI” has “stolen” my IP, and “AI” is coming for my (programming) job(s).), and quite unimpressed with the “AI” models I’ve interacted with especially in areas I’m an expert in, but also in areas where I’m not an expert for am very interested and capable of doing any sort of critical verification.
You might be interested in Lean.
Yes, I’ve written some Lean. It’s not my favorite programming language or proof assistant, but it seems to have “captured the zeitgeist” and has an actively growing ecosystem.
Fair enough. So what are your favorites?
Right now, I’m spending more time in Idris. It’s not a great proof assistant, but I think it’s a lot easier to write programs in. Rocq is the real proof assistant I’ve used, but I don’t have a strong opinion on them because all the proofs I’ve wanted/needed to write where small enough to need minimal assistance. (The bare bones features that are in Agda or Idris were enough.)
Also, my preference shouldn’t matter to anyone else. If you want to increase your proof assistant skill (even from nothing), I suggest lean. Probably the same if you want to increase programming skill in a dependently typed language.
Honestly, I should get more comfortable with it.
I just tried it on Braves AI

The obvious choice, said the motherfucker 😆
deleted by creator
Ai is not human. It does not think like humans and does not experience the world like humans. It is an alien from another dimension that learned our language by looking at text/books, not reading them.
It’s dumber than that actually. LLMs are the auto complete on your cellphone keyboard but on steroids. It’s literally a model that predicts what word should go next with zero actual understanding of the words in their contextual meaning.
and what is going to happen is that some engineer will band aid the issue and all the ai crazy people will shout “see! it’s learnding!” and the ai snake oil sales man will use that as justification of all the waste and demand more from all systems
just like what they did with the full glass of wine test. and no ai fundamentally did not improve. the issue is fundamental with its design, not an issue of the data set
The most common pushback on the car wash test: “Humans would fail this too.”
Fair point. We didn’t have data either way. So we partnered with Rapidata to find out. They ran the exact same question with the same forced choice between “drive” and “walk,” no additional context, past 10,000 real people through their human feedback platform.
71.5% said drive.
So people do better than most AI models. Yay. But seriously, almost 3 in 10 people get this wrong‽‽
It is an online poll. You also have to consider that some people don’t care/want to be funny, and so either choose randomly, or choose the most nonsensical answer.
Without reading the article, the title just says wash the car.
I could go for a walk and wash my car in my driveway.
Reading the article… That is exactly the question asked. It is a very ambiguous question.
*I do understand the intent of the question, but it could be phrased more clearly.
Without reading the article, the title just says wash the car.
No it doesn’t? It says:
I want to wash my car. The car wash is 50 meters away. Should I walk or drive?
In which world is that an ambiguous question?
Where is the car?
This is the exact question a person would ask when they to have a gotcha answer. Nobody would ask this question, which makes it suspect to a straight forward answer.
That’s a very good point! For that matter the car could still be at the bar where I got drunk and took an uber home last night. In which case walking or driving would both be stupid.
Or perhaps I’m in a wheelchair, in which case I wouldn’t really be ‘walking’.
Or maybe the car wash that is 50 meters away is no longer operating, so even if I walked or drove there, I still wouldn’t be able to walk my car.
Is the car wash self serve or one of the automatic ones? If it’s self serve what type of currency does it take? Does it only take coins or does it take card as well? If it takes coins, is there a change machine out front? Does the change machine take card or only bills? Do I even have my wallet on me?
There are so many details left out of this question that nobody could possibly fathom an answer!
…/s if it’s not obvious
The reason why your /s is there is for the same reason the question made no sense.
Opus 4.6 has been excellent at problem solving in software development, no surprises it nails it
It’s no surprise public opinion is these tools are trash when the free models are unable to answer simple questions
The free models feel years behind so people constantly underestimate what its capable of. I still hear people say ai can’t generate fingers.
No that is what the megacorps wishes. Open weight models are exactly as good but there are no commercial gpus for that so the point is only and only a class war issue
I am not able to test the open weight ones since I dont have 200gb+ of vram. So for now im gonna stay on my statement that the bleeding edge mega corp models are the best.
It is not true so you may stop if you want
What open weight model do you think is best right now?
M2.5 or whatever but it is the only one I tried
Even when they give the correct answer they talk too much. AI responses contain a lot of garbage. When AI gives you an answer it will try to justify itself. Since they won’t give you brief responses the responses will be long.
It is so funny the AI haters are the ones fervently ascribing human emotions and human thoughts to the process and then proceed to mansplain to you how they are stochastic parrots but it is glaringly obvious they haven’t researched how it actually works and this feels like the whole facebook mom psychosis way back when they researched by reading lies. No, their responses can be very short also. It depends on your temp
Your post is much longer than it needs to be. That is the reason why, because they just copied people.
I agree with you but found that DeepSeek was succinct.
You need to bring your car to the car wash, so you should drive it there. Walking would leave your car at home, which doesn’t help.
The second sentence is worthless garbage rambling that repeats the same point as the first sentence.
deleted by creator
There’s a difference between ‘language’ and ‘intelligence’ which is why so many people think that LLMs are intelligent despite not being so.
The thing is, you can’t train an LLM on math textbooks and expect it to understand math, because it isn’t reading or comprehending anything. AI doesn’t know that 2+2=4 because it’s doing math in the background, it understands that when presented with the string
2+2=, statistically, the next character should be4. It can construct a paragraph similar to a math textbook around that equation that can do a decent job of explaining the concept, but only through a statistical analysis of sentence structure and vocabulary choice.It’s why LLMs are so downright awful at legal work.
If ‘AI’ was actually intelligent, you should be able to feed it a few series of textbooks and all the case law since the US was founded, and it should be able to talk about legal precedent. But LLMs constantly hallucinate when trying to cite cases, because the LLM doesn’t actually understand the information it’s trained on. It just builds a statistical database of what legal writing looks like, and tries to mimic it. Same for code.
People think they’re ‘intelligent’ because they seem like they’re talking to us, and we’ve equated ‘ability to talk’ with ‘ability to understand’. And until now, that’s been a safe thing to assume.
Interesting, I tried it with DeepSeek and got an incorrect response from the direct model without thinking, but then got the correct response with thinking. There’s a reason why there’s a shift towards “thinking” models, because it forces the model to build its own context before giving a concrete answer.
Without DeepThink

With DeepThink

It’s interesting to see it build the context necessary to answer the question, but this seems to be a lot of text just to come up with a simple answer
The whole premise of deep think and similar in other models is to come up with an answer, then ask itself if the answer is right and how it could be wrong until the result is stable.
The seahorse emoji question is one that trips up a lot of models (it’s a Mandela effect thing where it doesn’t exist but lots of people remember it and as a consequence are firm that it’s real), I asked GLM 4.7 about it with deep think on and it wrote about two dozen paragraphs trying to think of everywhere a seahorse emoji could be hiding, if it was in a previous or upcoming standard, if maybe there was another emoji that might be mistaken for a seahorse, etc, etc. It eventually decided that it didn’t exist, double checked that it wasn’t missing anything, and gave an answer.
It was startlingly like stream of consciousness of someone experiencing the Mandela effect trying desperately to find evidence they were right, except it eventually gave up and realized the truth.
EDIT: Spelling. Really need to proofread when I do this kind of thing on my phone.
yeah i find the thinking fascinating with maths too… like LLMs are horrible at maths but so am i if i have to do it in my head… the way it breaks a problem down into tiny bits that is certainly in its training data, and then combine those bits is an impressive emergent behaviour imo given it’s just doing statistical next token
Your verbal faculties are bad at math. Other parts of your brain do calculations.
LLMs are a computer’s verbal faculties. But guess what, they’re just a really big calculator. So when LLMs realize that they’re doing a math problem and launch a calculator/equation solver, they’re not so bad after all.
that solver would be tool use though… i’m talking about just the “thinking” LLMs. it’s fascinating to read the thinking block, because it breaks the problem down into basic chunks, solves the basic chunks (which it would have been in its training data, so easy), and solves them with multiple methods and then compares to check itself
They’re showing the thinking the model did, the actual response is the sentence at the end.
Hey LLM, if I have a 16 ounce cup with 10oz of water in it and I add 10 more ounces, how much water is in the cup?
Qwen3-4B HIVEMIND
You now have 16 ounces of water in the cup. The cup can hold 16 ounces, so the rest is over capacity.
Confidence: unverified | Source: Model
What a great idea! Would you like me to write up a business plan for your new water company?
I want to wash my train. The train wash is 50 meters away. Should I walk or drive?
Fly, you fool
In school we were taught to look for hidden meaning in word problems - checkov’s gun basically. Why is that sentence there? Because the questions would try to trick you. So humans have to be instructed, again and again, through demonstration and practice, to evaluate all sentences and learn what to filter out and what to keep. To not only form a response, but expect tricks.
If you pre-prompt an AI to expect such trickery and consider all sentences before removing unnecessary information, does it have any influence?
Normally I’d ask “why are we comparing AI to the human mind when they’re not the same thing at all,” but I feel like we’re presupposing they are similar already with this test so I am curious to the answer on this one.
Normally I’d ask “why are we comparing AI to the human mind when they’re not the same thing at all,” but I feel like we’re presupposing they are similar already with this test so I am curious to the answer on this one.
I would guess it’s because a lot of AI users see their choice of AI as an all-knowing human-like thinking tool. In which case it’s not a weird test question, even when the assumption that it “thinks” is wronh
I tried this with a local model on my phone (qwen 2.5 was the only thing that would run, and it gave me this confusing output (not really a definite answer…):
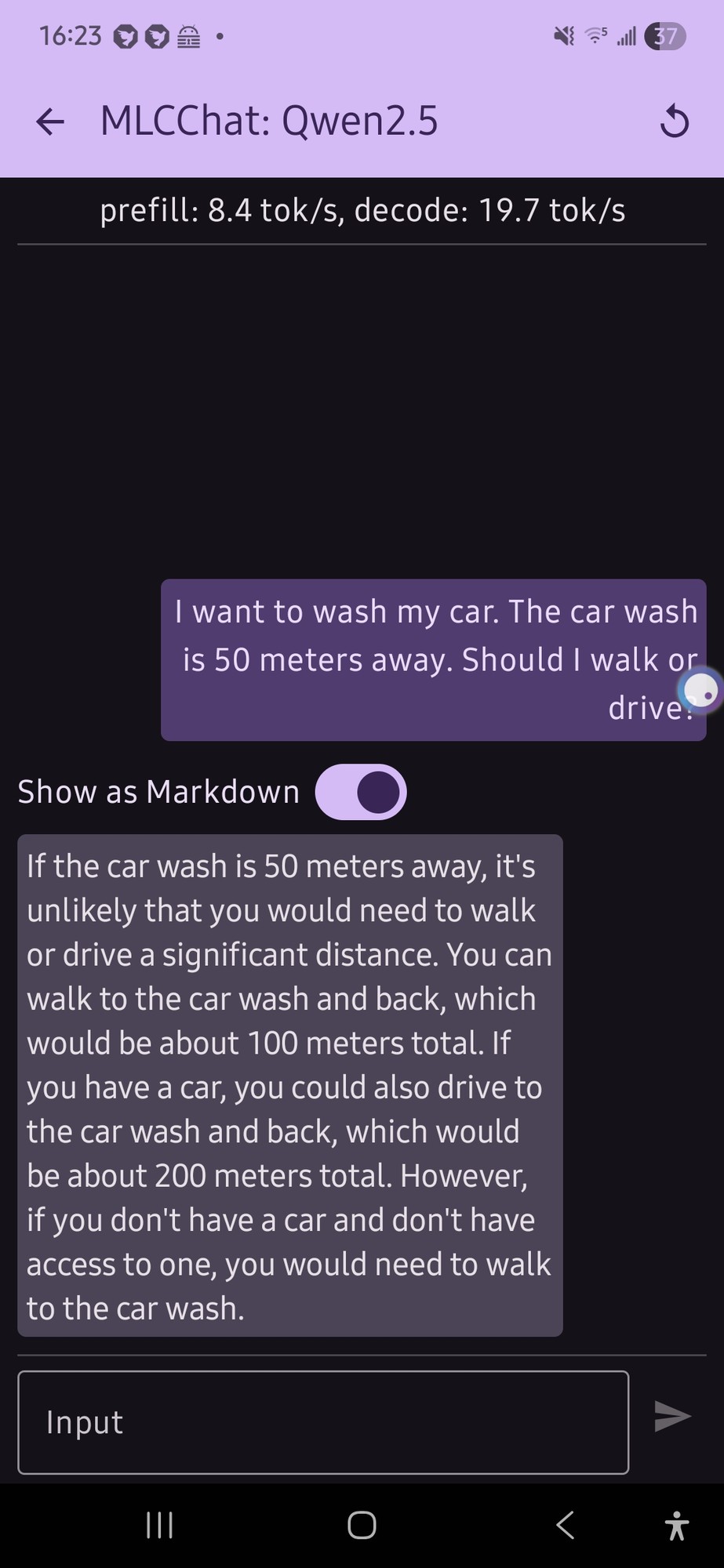
it just flip flopped a lot.
E: also, looking at the response now, the numbers for the car part doesn’t make any sense
I like that it’s twice as far to drive for some reason. Maybe it’s getting added to the distance you already walked?
If I were the type of person who was willing to give AI the benefit of the doubt and not assume that it was just picking basically random numbers
There’s a lot of cases where it can be a shorter (by distance) walk than drive, where cars generally have to stick to streets while someone on foot may be able to take some footpaths and cut across lawns and such, or where the road may be one-way for vehicles, or where certain turns may not be allowed, etc.
I have a few intersections near my father in laws house in NJ in mind, where you can just cross the street on foot, but making the same trip in a car might mean driving half a mile down the road, turning around at a jug handle and driving back to where you started on the other side of the street.
And I wouldn’t be totally surprised if that’s the case for enough situations in the training data where someone debated walking or driving that the AI assumed that it’s a rule that it will always be further by car than on foot.
That’s still a dumbass assumption, but I’d at least get it.
And I’m pretty sure it’s much more likely that it’s just making up numbers out of nothing.













